文字コード的に見たフォント設計の自由度 ― 2007年10月30日 21:41
JIS X 0208:1997の公開レビューがインターネットで行われていたのはご存じでしょうか。当時はFTPでレビュー資料をダウンロードする形態をとっていました。ネットニュース(fjニュースグループ)でお知らせが回っていたような覚えもあります。
レビュー資料のことはもうほとんど忘れてしまいましたが、FAQの中にイカした項目があったのは覚えています。たしか、低解像度のビットマップフォントなどで点画の省略をしても規格に適合するという話の後だったと思うのですが、
問: 1区1点から、区点位置をひとつずつずらして、「亜」の区点位置に「唖」の字形、「唖」の区点位置に「娃」、「娃」の位置に「阿」……として実装したフォントはこの規格に適合しますか? これなら、それぞれの文字は他のいかなる図形文字とも区別できますよ。
答:適合しません。区点位置に定義されている文字を想起できないからです。
なにぶん10年以上前の記憶なので細かいところは違っているかもしれませんが、概略こんな項目だったと思います。
これは、文字コード規格がフォント実装に要求するものを考える上で示唆的な話です。
97JISの「3.3.3 受信装置」は、装置が「符号化文字を受信し」「対応する文字を」「利用者に渡さなければならない」として、(回りくどい表現ではありますが) バイト表現を解釈しフォントを印字する際の要件を示しています。
上の架空のやり取り (FAQと称していても、実際はnever asked questionなことってありますよね) の意地悪な問いは、ここで述べられている、符号化文字に対応する文字を渡すという点において、規格の規定から外れてしまうわけです。「亜」の符号を受信した装置は、利用者がその符号位置に対応する文字 (「亜」) だと認識できる図形を出力しなければならないわけです。まあ、常識で考えればいい話ではあるんですが。
同じ節はまた、受信装置に表現上の制約がある場合は点画の省略を行っても良いが、他の文字と区別できることを要求しています。また、その際に包摂規準を越えた点画の省略をも許しています。これは、16ドットフォントで「量」を作ろうとするとどこかの横線を省かないとできない(当然、包摂規準でそんな字体差は包摂できない)といった事情を救済するためのものです。全然違う字体を採用することを許容するものではありません。中国簡体字をまねて「機」を「机」にするなどまるっきり違う字体に簡略化してしまうと、上のFAQと同じ要領で不適合とみなされることになります。
こうしてみると、文字コード値に対応させて出力する字形というのは、
- その符号位置に対応する文字を、文字集合内の他の文字と紛れのないように表示すべきであり、
- 可能な字体差は包摂規準に示されており、
- ただし表示装置が貧弱な場合は妥当な簡略化も許容するが、だからといってなんでもいいわけではない
といった条件を満たすべきということになります。実は規格本文を見ると分かりますが、これでもまだ端折った内容があります。これ以上は面倒くさいので勘弁。
だからたとえば、「辻」に対応する符号を受け取った装置は、利用者が他のどの文字でもない「辻」のことだなとわかるような字形を表示すればよいわけです。その際、しんにょうの点のがひとつかふたつかなどは書体設計者の自由ですが、世間一般でいう「辻」だと認識できないようなつくりであってはいけないわけです。
よく考えれば常識的なことなのに、言葉にされるとなんだかえらく面倒な感じがするものですね。
フォントの字体変更は文字コードの話題か? ― 2007年10月30日 00:03
JIS X 0213:2004が (包摂の範囲内で) 例示字形を変更したために、この変更に追随して字体設計を変更するフォントがいくつかあるようです。「辻」のしんにょうが1点か2点か、というのはこのレベルの話です。さて、これは文字コードの話題でしょうか?
文字コードとは、文字とバイト表現との対応を規定するものです。あるバイト表現に対応する文字がどのような字体をとるかは、包摂の範囲内において、設計者の方針次第です。文字コードの問題ではありません。JIS X 0208/0213では、しんにょうの点が1点か2点かは、文字コードとして区別しないことが明記されています。
なので、「辻」のしんにょうの点の数の如き問題は、文字コードの話題ではありません。フォントの話です。文字コードについて雑誌記事などを書く人におかれては、是非こうした区別に敏感であってほしいと思います。
補足すると、字体変更が包摂規準の範囲を越えて行われると、文字コード規格に適合するかどうかの問題が生じるので、文字コードの話題ともなり得ます。
文字コードに対する3つのスタンス ― 2007年05月06日 12:19
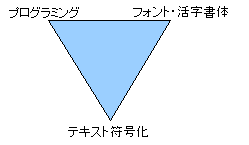
文字コードについての意見や議論は、その人の立場によって立脚点や基本的なものの見方がかなり異なっており、そのことが相互の理解を難しくしていると感じることがあります。
私が考える3つのスタンスを図に表してみました。それぞれのスタンスをステレオタイプ的に描画すると以下のようになります。
- プログラミング系
文字コードをバイト値として扱うことに詳しい。文字コードがどのような特徴を持っていればプログラミングが楽になるかという観点が強い。一方、コード値に対応する文字そのものがどう定義されているかにはあまり興味がない。文字の定義は規格を決めた人がうまくやっているはずだと考えている。「Unicodeさえあれば良い」と考えがちなのもこのタイプ。
- フォント・活字書体系
フォント設計の微細なところまで知りつくしている。文字コード規格の例示字形に詳しく、常人には区別のつかないわずかな違いも見逃さない。フォント技術に詳しいが、文字コードはフォントによる字形表現のためにあるものととらえがち。包摂規準の意義を理解していることもあるが、「所詮は規格票の字形が全て」と達観する人も。
- テキスト符号化系
紙の上などに表現された現実の文字を、文字コード規格に沿った形でデジタル化することに喜びを覚える。文書の符号化、書誌データベースの整備、仮名漢字変換辞書の開発などに携わる。文字を符号化するという意味において文字コード規格の根元的な利用者であるが、人数が絶対的に少ないのと言うことが難しいために彼らの声は世間に届きにくい。包摂規準を重視する。
どのスタンスが正しいということではなく、肝心なのは相互理解であろうと思います。
ちなみに私自身は、「プログラミング系」と「テキスト符号化系」の中間あたりに位置します。
これをお読みの方は、ご自身の立ち位置を振り返って、自分に足りない要素は何だろうかと自問してみるのも一興かと思います。
最近のコメント